
Abstract
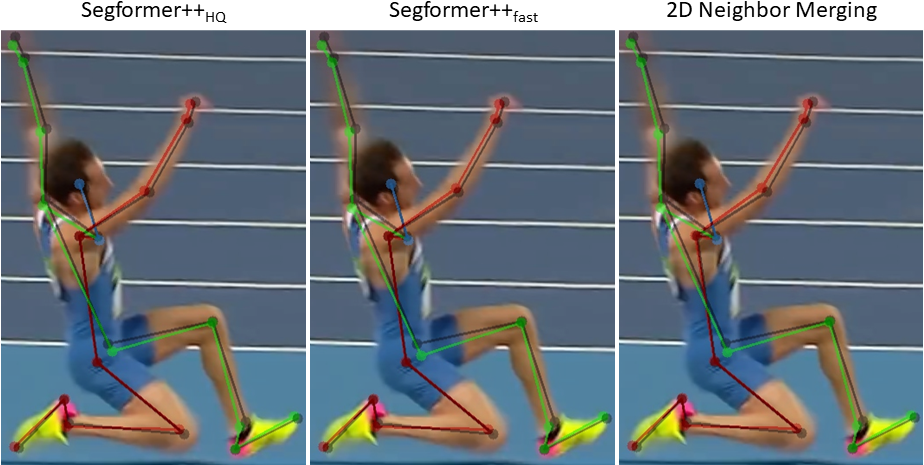
Utilizing transformer architectures for semantic segmentation of high-resolution images is hindered by the attention's quadratic computational complexity in the number of tokens. A solution to this challenge involves decreasing the number of tokens through token merging, which has exhibited remarkable enhancements in inference speed, training efficiency, and memory utilization for image classification tasks. In this paper, we explore various token merging strategies within the framework of the Segformer architecture and perform experiments on multiple semantic segmentation and human pose estimation datasets. Notably, without model re-training, we, for example, achieve an inference acceleration of 61% on the Cityscapes dataset while maintaining the mIoU performance. Consequently, this paper facilitates the deployment of transformer-based architectures on resource-constrained devices and in real-time applications.
Links
Our paper was accepted at IEEE International Conference on Multimedia Information Processing and Retrieval (MIPR) 2024. Find the paper, oral presentation, code, and weights below.
Citation
If you find this paper helpful, please consider citing:
@article{kienzlemipr2024,
author = {Daniel Kienzle and Marco Kantonis and Robin Schön and Rainer Lienhart},
title = {Segformer++: Efficient Token-Merging Strategies for High-Resolution Semantic Segmentation},
journal = {Proceedings of the 7th International Conference on Multimedia Information Processing and Retrieval (MIPR)},
year = {2024},
}
License
The structure of this page is taken and modified from nvlabs.github.io/eg3d which was published under the Creative Commons CC BY-NC 4.0 license .